Dockerを使ってTsurugi環境構築を行う際の注意点
はじめに
このエントリは Tsurugi Advent Calendar 2023 の17日目のエントリです。前日は hishidama さんによる「 Tsurugiのdrop table 」でした。
Tsurugiに限らず、最近は手元で開発用のサーバー類を立ち上げたい場合、Dockerコンテナとして立ち上げるのが楽ですよね。簡単に環境を構築できて簡単に捨てられるので。
TsurugiももちろんDockerイメージが用意されているので簡単にサーバーを立ち上げて開発を始めることができます (公式のDockerユーザーガイドのリンク) 。 ただ自分がTsurugiのDockerコンテナを立ち上げた際にいくつか引っ掛かったことがあったので、このエントリではその内容について触れていきます。
Dockerイメージの入手と起動
TsurugiのDockerイメージは Github Container Registry 上で公開 しています。
次のように docker pull する際に ghcr.io を頭に付けると引っ張ってこれます。
docker pull ghcr.io/project-tsurugi/tsurugidb:latest
本エントリ執筆時点では latest タグで 1.0.0-BETA2 が落ちてきます。
バインドするポートを指定して起動すれば、そのまま立ち上がります。
docker container run -d -p 12345:12345 --name tsurugi ghcr.io/project-tsurugi/tsurugidb:latest
TCP12345ポートで接続を受け付けるので、SQLコンソールである Tanzawa やJava APIの Iceaxe で12345ポートに接続して利用します。
設定ファイルをホスト管理する方法とその際の注意点
Dockerコンテナとしてサーバーを管理していても、設定ファイル類などはホスト側で管理したいことが多いと思います。TsurugiのDockerイメージでは設定ファイル格納ディレクトリは /usr/lib/tsurugi/var/etc になっているので、このディレクトリをホスト側の任意のディレクトリとバインドマウントします。
docker container run -d -p 12345:12345 -v <ホスト側のパス>:/usr/lib/tsurugi/var/etc --name tsurugi ghcr.io/project-tsurugi/tsurugidb:latest
ここでまず注意点があります。 /usr/lib/tsurugi/var/etc とバインドしたホスト側のディレクトリに設定ファイル tsurugi.ini が配置されていないと次のようなログを残してTsurugiが起動に失敗します。
could not launch tsurugidb, as cannot find any valid configuration file
設定ファイルが存在しない状態では起動できません。そのため必ずこのディレクトリに tsurugi.ini を配置して起動してください。
tsurugi.ini に記載する設定項目には初期値が設定されているため、ほとんどの項目は記載しなくても動きます。ですが datastore セクションの log_location だけは例外で、この設定が記述されていない場合 データが永続化されません 。
ただのオンメモリデータベースになってしまい、コンテナを停止して起動すると登録したデータが失われてしまいます。
TsurugiのDockerイメージでは $TSURUGI_HOME/var/data/log がトランザクションログの保存ディレクトリとして作られているので、次のように設定を記入してください。
[datastore] log_location=var/data/log
コンテナを削除してもデータを残す方法
コンテナとしてデータベースを利用している場合、データはコンテナ外に保存してコンテナを作り直しても継続して利用できるようにすることが多いと思います。
先にも書いたように $TSURUGI_HOME/var/data/log がトランザクションログの保存ディレクトリであるため、このディレクトリをバインドすればいいです。次にボリューム (ここではボリュームの名前を tsurugivol としています) にマウントする例を示します。
docker container run -d -p 12345:12345 -v tsurugivol:/usr/lib/tsurugi/var/data --name tsurugi ghcr.io/project-tsurugi/tsurugidb:latest
以上、自分が引っ掛かった経験を元に注意点をまとめました。コンテナ技術を使えばお手軽に試すことができるので、みんなどんどんTsurugiで遊んでみてください。
DiigoからRaindrop.ioへPandasを使って移行した話
ブックマークサービスの移行について
自分は基本的にWebサイトのブックマークはWebサービスを利用するようにしているのですが、長らくその目的にDiigoを利用していました。
日本ではオンラインブックマークサービスとしては圧倒的にはてなブックマークが有名ですが、はてなに無い機能として「ブックマークしたWebページにハイライトやメモの追加を行うことができる」というものがあり、これが便利だったのではてなから乗り換えました。
課金も行って便利に使っていたDiigoですが、近年は開発が停滞しているように見受けられ(ブログも5年ほど更新されてしません)、将来性が不安になってきていました。 そんなところに次のRaindrop.ioというオンラインブックマークサービスがあることを知りました。
raindrop.io Raindrop.ioは次のような特徴を持つオンラインブックマークサービスです。
- Diigoと同様、ブックマークしたWebサイトに対して文章にハイライトを引いたり、メモを記入することができる
- ブックマークはコレクション(フォルダと同義)とタグという2種類の整理方法がある
- ブックマークの内容を分析して自動的にカテゴリ分けしてくれる機能もある
- Webブラウザ向け拡張機能やモバイルアプリケーションももちろん提供している
- Diigoのモバイルアプリはブラウザが前面に出てくるインターフェースだったのが使い辛かった
総じてDiigoの機能は全て保持しており、開発も盛んに行われている印象だったので乗り換えてみることにしました。
どのようにしてデータを移行するか
乗り換えるためにはデータの移行が必要です。可能ならば次の情報を持っていきたいと考えていました。
- URL
- ブックマークタイトル
- エントリに対して自分が記入した説明
- ブックマークに付けたタグ
- ブックマークした日時
- Webサイトの情報は陳腐化が激しいのでいつブックマークしたかの情報は重要
さすがにWebページのハイライトやノートの情報までは持っていくことは考えませんでした。
Diigo側では次のような形式でデータのエクスポートが可能でした (Diigoのエクスポートページ) 。
| エクスポート形式 | 出力する内容 |
|---|---|
| IEブックマーク | URL、タイトル |
| Firefoxブックマーク | URL、タイトル、タグ |
| RSS | URL、タイトル、説明、タグ、Webページのハイライトやメモの情報 |
| CSV | URL、タイトル、説明、タグ、Webページのハイライトやメモの情報 |
| Chromeブックマーク形式 | URL、タイトル (今は亡きdel.icio.us互換らしい) |
一方Raindrop.io側では次のような形式でのインポートが可能です (Raindropのインポート形式についての説明) 。
- 各種Webブラウザーのブックマーク
- CSV
- プレーンテキスト
- EvernoteのENEX
- Twitterのブックマーク
- Raindropが用意したWebサービス を使ってエクスポートする
- Edgeコレクション
というわけで多くの情報を持っていくにはCSVで移行するのが一番良さそうだと分かりました。
Pandasを使ってCSVのフォーマットを合わせる
DiigoからエクスポートしたCSVは次のようなカラム構成でした。
| カラム名 | 内容 |
|---|---|
title |
ブックマークタイトル |
url |
ブックマークのURL |
tags |
ブックマークに付けられたタグ |
description |
ブックマークに付けた説明文 |
comments |
Webページに添付したノート |
annotations |
WebページのハイライトをHTMLとして出力している |
createt_at |
ブックマーク作成日時をUTCで出力 (%Y-%m-%d %H:%M:%S フォーマット) |
一方Raindrop.io側はインポートするCSVのカラム構成を次のように定めています。
カラム順は問わず、必須なのは url カラムのみです。
| カラム名 | 内容 |
|---|---|
url |
ブックマークのURL |
folder |
ブックマークが保存されているフォルダー |
url |
ブックマークのURL |
note |
ブックマークに付けられた説明文 |
tags |
ブックマークに付けられたタグ |
created |
ブックマーク作成日時をUNIXタイムスタンプもしくはISO8601形式で |
Diigoから出力されたCSVから次のような変換を行う必要がありますね。
comments及びannotationsカラムを削除- カラム名
descriptionをnoteにリネーム - カラム
created_atの日時文字列をISO8601形式に変換する - カラム名
created_atをcreatedにリネーム
Pandasを使ってこの変換処理を行いました。Jupyter Notebookを使って実行しています。Jupyterは動かした結果をその場で見ながら試行錯誤できて便利ですね。
まずCSVをPandasを使って読み込みます。UTF-8のCSVなのでそのまま読み込めます。
df = pd.read_csv("<path to input CSV>")
日時のフォーマットを変換します。まずは created_at カラムを datetime 型に変換します。
df["converted_dt"] = pd.to_datetime(df["created_at"], errors="coerce", utc=True)
Pandasは日付っぽい文字列に対してフォーマットを指定せずともある程度よろしく解釈してくれます。時刻はUTCなので utc=True を指定しています。
今度はISO8601形式の文字列に変換します。Raindropが要求するカラム created に出力します。
df["created"] = df["converted_dt"].dt.strftime("%Y-%m-%dT%H:%M:%SZ")
次にカラム名のリネームをします。
df = df.rename(columns={"description": "note"})
最後に必要なカラムだけを選択して、出力用DataFrameを作成し、CSVファイルとして出力します。
output_df = df[["url", "title", "note", "tags", "created"]] output_df.to_csv("<path to output CSV>", index=False, quoting=csv.QUOTE_NONNUMERIC)
文字列には改行も入っているのでCSVのクォートは csv.QUOTE_NONNUMERIC を指定しました。
このファイルをRaindrop.ioに読み込ませると無事インポートに成功しました!
Diigoではこうだったのが...

Raindrop.io側にこのようにちゃんと引き継がれました。タグや登録日時の情報も引き継がれています。

復活していたQtJambi
QtJambiの開発は引き継がれていた
OracleからJavaのクライアントテクノロジーに関するロードマップが発表され、それについて色々思うことを垂れ流した次のブログを投稿したのですが、あれからもう5年になるのですね。
aoe-tk.hatenablog.com aoe-tk.hatenablog.com
このエントリにて、次のようなことを書いていました。
汎用的なクロスプラットフォーム GUI で一番成功しているのはやはり Qt でしょうか。モバイルへの進出にも成功していますし。開発言語は C++ ですが、他のプログラミング言語へのバインディング も多いです。ですが、Java バインディングである Jambi が死んでしまったんですよね...。
QtのJavaバインディングであるJambiについて、このエントリを書いたときは死んだような状態になっていたのですね。ところが最近QtJambiという名称として (以前は "Qt Jambi" とQtとJambiの間にスペースが入っていました) 復活していたことに気付きました。
これは元々NokiaがQt JambiのOSS化にあたって作った 旧Qt Jambiのリポジトリ とは別のリポジトリです。 どうもOmix Visualizationという会社が最新のQtに対応したフォークを作成して開発を引き継いだようです。旧リポジトリでは対応していなかったQt5系はもちろん、6系も最新の6.5にまで対応したリリースがあります。
コミット履歴を調べてみると *1 一番最初のコミットは2015年9月で、旧リポジトリの最後のコミットが2015年9月であるのを見るに、旧プロジェクトの開発終了後すぐに新しいリポジトリを作ったようです。旧プロジェクトにてコミッタ間で話し合いがあってフォークが決まったとかですかねえ。
リポジトリ作成は2015年9月ですがリリースタグの付いた最初のリリースは2020年8月で、ここからプロダクトとしてリリースしていくステップに入ったようです。 Qt本家Wikiの言語バインディングのページ に追加されたのもその時からでした。旧プロジェクトの終了後、5年のブランクを経て復活した形ですね。
触ってみる
見つけたからには触ってみることにしましょう。なお自分はQtによる開発の経験は過去に一切ありません🙂
QtJambiはJPMSに従ったモジュール化がされています。次のAPIドキュメントのトップメージにモジュール一覧が列挙されています。Qtが提供する膨大なライブラリを概ねカバーしているようです。3DやWebViewなどはもちろん、BluetoothやNFC、センサーなど実に膨大な範囲をカバーしていることが分かりますね。
https://doc.qtjambi.io/latest/
基本的なものは全て qtjambi モジュールに入っています。モジュール別にMaven Centralに登録されているので、Mavenを使っている場合は pom.xml に次のように依存設定を追加します。実行にあたってはプラットフォームに応じたネイティブライブラリも必要なので qtjambi-native-<os>-<architecture> も追加する必要があります。
<dependencies> <dependency> <groupId>io.qtjambi</groupId> <artifactId>qtjambi</artifactId> <version>6.5.0</version> </dependency> <dependency> <groupId>io.qtjambi</groupId> <artifactId>qtjambi-native-windows-x64</artifactId> <version>6.5.0</version> </dependency> </dependencies>
これでプログラムを作成できます。ごく簡単なウィンドウとメニューを持つアプリケーションを作ってみます。
package aoetk.qtsamle; import io.qt.gui.QAction; import io.qt.widgets.QApplication; import io.qt.widgets.QLabel; import io.qt.widgets.QMainWindow; import io.qt.widgets.QMenu; import static io.qt.core.QObject.tr; import static java.util.Objects.requireNonNull; public class WindowSample { public static void main(String[] args) { QApplication.initialize(args); QMainWindow mainWindow = new QMainWindow(); QMenu menu = requireNonNull(mainWindow.menuBar()).addMenu(tr("&File")); QAction quitAction = requireNonNull(menu).addAction(tr("&Quit")); requireNonNull(quitAction).triggered.connect(QApplication::quit); mainWindow.setCentralWidget(new QLabel(tr("Hello Qt!"), mainWindow)); mainWindow.show(); QApplication.exec(); QApplication.shutdown(); } }
実行するにあたっては予めQtがインストールされている必要があります。 インストーラのダウンロードページ からQtのインストールを行います。予めユーザー登録を行う必要がある点に注意してください。非常に巨大なライブラリなのでインストールには結構時間が掛かります。
作ったJavaアプリケーションを実行する際、JVMシステムプロパティ java.library.path にQtのライブラリパスを指定します。OS別に次のようなパスになります。
- Windows
<path to>\Qt\<version>\msvc2019_64\bin
- Linux
<path to>/Qt/<version>/gcc_64/lib
- macOS
<path to>/Qt/<version>/macos/lib- macOSの場合はさらに起動引数として
-XstartOnFirstThreadを指定する必要あり
Windows環境のIntelliJでの実行設定の例を示しておきます。
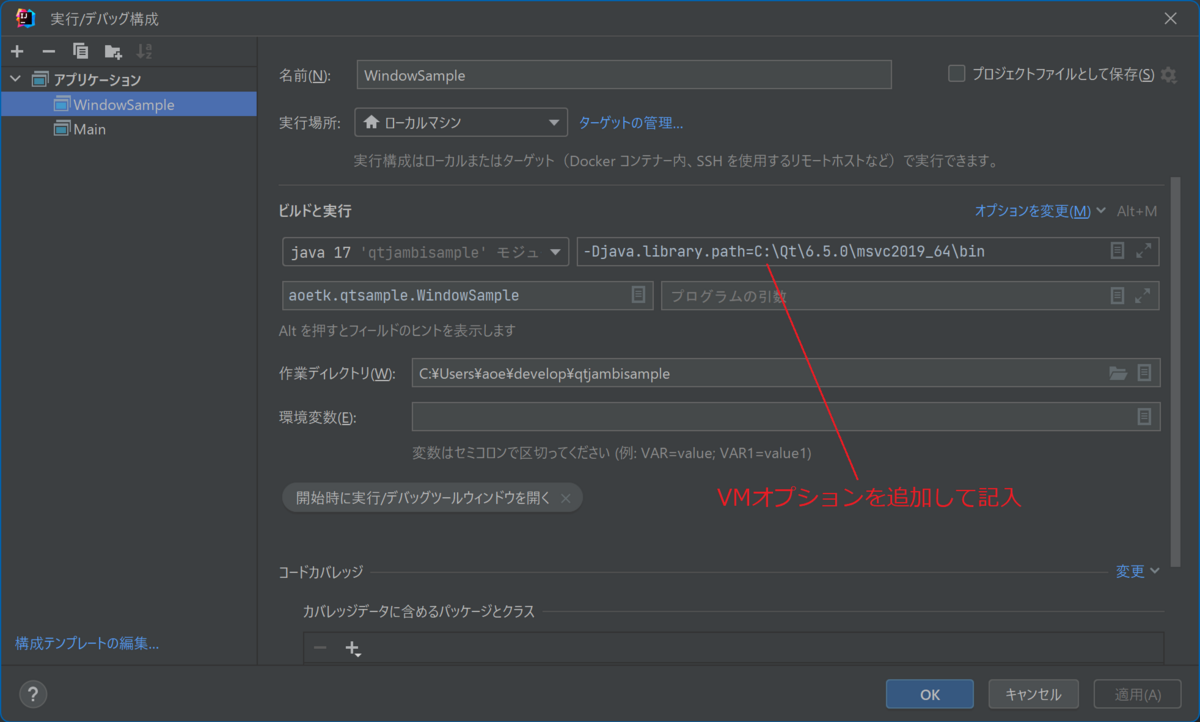
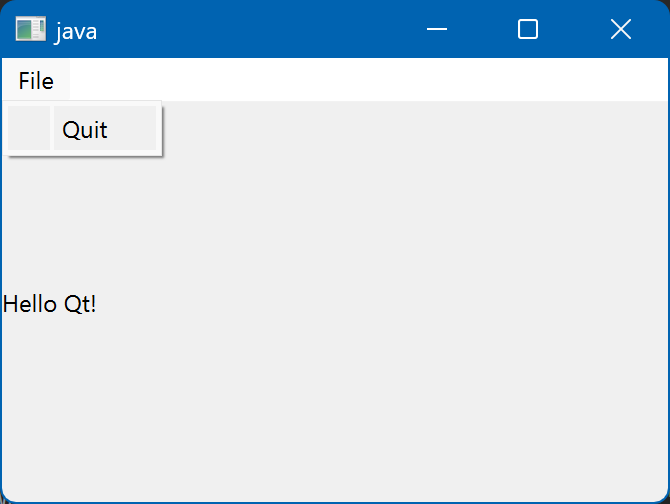
プログラムを実行すると次のようにメニューとラベルを持つウィンドウが起動しました。
使い方を学ぶには?
汎用クロスプラットフォームGUIツールキットとしては最強と思われるQtへのバインディングが提供されたことで、再びJavaにもスタンドアロンGUIアプリケーションを作るための強力な手段が加わりました。
現時点での問題点は余りにも情報が少ないという点ですね。GoogleやTwitter、Stack Overflowなどを検索してもこの新しいQtJambiへの言及がほとんど見られていません。本当に一握りの人間しかこれの存在に気付いていないような気がしますw
基本的にドキュメントは GitHubプロジェクト上のWiki からたどれる範囲のみで、Qtについての基本概念は知っていることを前提とした記述になっています。APIドキュメントについても本家C++版のページへのリンクを示すだけのクラスが多いです。
自分はC++の開発経験がゼロに等しいので、C++版のドキュメントを読むのはちょっと辛いんですよねえ。幸いQtは有名どころのプログラミング言語に対してはほぼバインディングを提供しており、例えばPythonバインディングであるQt for Python (PySide) については公式からも豊富なドキュメントが提供されているので、これでQtを勉強しますかねえ。
というわけでいつの間にか復活していたQtJambiについての紹介でした。
PySparkでコントロールブレイク処理
お題は次のエントリです。
上記エントリではいわゆるコントロールブレイク処理(ソート済みのレコードを読み込み、キー項目ごとにグループ分けして行う処理のことでキーブレイク処理と呼ぶことも)を 1 本の SQL でスマートに行っています。これと同じことを PySpark でやってみるという話です。
次のような CSV ファイルを用意しておきます。
sales_date,jan_code,sales_cnt 2014/10/06,AAA,100 2014/10/07,AAA,200 2014/10/08,BBB,100 2014/10/09,BBB,150 2014/10/10,BBB,189 2014/10/11,CCC,120 2014/10/12,CCC,111 2014/10/13,AAA,210 2014/10/14,AAA,545 2014/10/15,AAA,90 2014/10/16,CCC,90
これを Spark DataFrame に読み込みます。
from pyspark.sql.types import StructType, StructField, StringType, IntegerType, DateType schema = StructType([ StructField('sales_date', DateType()), StructField('jan_code', StringType()), StructField('sales_cnt', IntegerType()) ]) df = spark.read.csv('<path-to-csv>', schema=schema, header=True, dateFormat='yyyy/MM/dd') df.show() # +----------+--------+---------+ # |sales_date|jan_code|sales_cnt| # +----------+--------+---------+ # |2014-10-06| AAA| 100| # |2014-10-07| AAA| 200| # |2014-10-08| BBB| 100| # |2014-10-09| BBB| 150| # |2014-10-10| BBB| 189| # |2014-10-11| CCC| 120| # |2014-10-12| CCC| 111| # |2014-10-13| AAA| 210| # |2014-10-14| AAA| 545| # |2014-10-15| AAA| 90| # |2014-10-16| CCC| 90| # +----------+--------+---------+
元の SQL では ROW_NUMBER ウィンドウ関数を使って単純ソートした場合の連続値と jan_code で区切りつつソートした場合の連続値を割り振っていますが、PySpark (Spark SQL) でも pyspark.sql.functions.row_number という同じ関数があります。
from pyspark.sql import Window from pyspark.sql.functions import row_number # SQLでの ROW_NUMBER() OVER(ORDER BY SALES_DATE) に相当 df = df.withColumn('simple_sq', row_number().over(Window.orderBy('sales_date'))) # SQLでの ROW_NUMBER() OVER(PARTITION BY JAN_CODE ORDER BY SALES_DATE) に相当 df = df.withColumn('part_jan_sq', row_number().over(Window.partitionBy('jan_code').orderBy('sales_date')))
パーティションとソート順は pyspark.sql.Window クラスのファクトリメソッドを使って生成する pyspark.sql.WindowSpec オブジェクトとして渡します。
あとは distance を計算すれば集約カラムが作られますね。
from pyspark.sql.functions import col df = df.withColumn('distance', col('simple_sq') - col('part_jan_sq')) df.orderBy('sales_date').show() # +----------+--------+---------+---------+-----------+--------+ # |sales_date|jan_code|sales_cnt|simple_sq|part_jan_sq|distance| # +----------+--------+---------+---------+-----------+--------+ # |2014-10-06| AAA| 100| 1| 1| 0| # |2014-10-07| AAA| 200| 2| 2| 0| # |2014-10-08| BBB| 100| 3| 1| 2| # |2014-10-09| BBB| 150| 4| 2| 2| # |2014-10-10| BBB| 189| 5| 3| 2| # |2014-10-11| CCC| 120| 6| 1| 5| # |2014-10-12| CCC| 111| 7| 2| 5| # |2014-10-13| AAA| 210| 8| 3| 5| # |2014-10-14| AAA| 545| 9| 4| 5| # |2014-10-15| AAA| 90| 10| 5| 5| # |2014-10-16| CCC| 90| 11| 3| 8| # +----------+--------+---------+---------+-----------+--------+
集約のためのキーができたので、集約を行っておしまい。
grouped_df = df.groupBy(['jan_code', 'distance']) \ .agg(min('sales_date').alias('sales_date_first'), \ max('sales_date').alias('sales_date_last'), \ sum('sales_cnt').alias('cnt_sum')) grouped_df.orderBy('sales_date_first').show() # +--------+--------+----------------+---------------+-------+ # |jan_code|distance|sales_date_first|sales_date_last|cnt_sum| # +--------+--------+----------------+---------------+-------+ # | AAA| 0| 2014-10-06| 2014-10-07| 300| # | BBB| 2| 2014-10-08| 2014-10-10| 439| # | CCC| 5| 2014-10-11| 2014-10-12| 231| # | AAA| 5| 2014-10-13| 2014-10-15| 845| # | CCC| 8| 2014-10-16| 2014-10-16| 90| # +--------+--------+----------------+---------------+-------+
PySparkでの時刻変換色々
最近はデータエンジニアリングのお仕事がメインで、もっぱら PySpark を触っています。 自分向けの備忘録的も兼ねてちょいちょい blog に tips を書いていきたいと思います。
今回は時刻変換に関するもの。
タイムゾーン付き日付文字列をパースしてtimestamp型に変換
基本は to_timestamp 関数を使います。
from pyspark.sql.functions import col, to_timestamp df = spark.createDataFrame([('2021-05-16T23:03:49.220Z',)], ['str_datetime']) df = df.withColumn('datetime', to_timestamp(col('str_datetime'), "yyyy-MM-dd'T'HH:mm:ss.SSSX"))
日時フォーマットのパターン文字列は Java方式 です。Spark は Scala で作られているので、Python でコードを書いていてもこういうところで Java が顔を出してきます。
似たものとしてUNIX時間に変換する unit_timestamp という関数がありますが、こちらはミリ秒以下が切り捨てられることに注意してください。
from pyspark.sql.functions import unix_timestamp from pyspark.sql.types import TimestampType df = df.withColumn('time', unix_timestamp(col('str_datetime'), "yyyy-MM-dd'T'HH:mm:ss.SSSX").cast(TimestampType()))
日付文字列をdate型に変換
to_date 関数を使います。
from pyspark.sql.functions import to_date df = df.withColumn('date_col', to_date(col('str_datetime'), "yyyy-MM-dd'T'HH:mm:ss.SSSX"))
ゾーン情報を使ってローカル時刻にタイムスタンプをずらす
from_utc_timestamp 関数を使います。 現地時刻に変換した文字列を取得したい時やタイムゾーン情報のないデータベースに登録するときとかに使うかも。
from pyspark.sql.functions import from_utc_timestamp df = df.withColumn('local_time', from_utc_timestamp(col('time'), 'Asia/Tokyo'))
date型、timestamp型のカラムを手動作成する
Python の datetime.date 型で値を投入すると Spark SQL の DateType になります。
同様に datetime.datetime 型で値を投入すると Spark SQL の TimestampType になります。
import datetime a_date = datetime.date(2022, 1, 1) a_datetime = datetime.datetime(2022, 1, 1, hour=1, minute=10, second=10, microsecond=100000) df = spark.createDataFrame([(a_date, a_datetime)], ('date_col', 'time_col'))
SoftBank回線でSIMフリースマートフォンに乗り換えたら大変だった話
前置き
これまでスマートフォンとして 3 年前に購入した Pixel 3 XL を使い続けていましたが、さすがにバッテリーがへたってきており、もうすぐサポート期間の終了を迎えることもあって別の機種に乗り換えることになりました。
もうすぐ登場する Pixel 6 を当初は考えていたのですが、非常に高価になるという話で、また端末サイズも今使っている Pixel 3 XL よりさらに大きくなるという話なので、別のものも探してみることにしました。
色々探してみたところ、ASUS からリリースされたばかりの Zenfone8 が良さそうということでこれを購入しました。
購入判断の根拠は次のようなところです。
- Qualcomm の最新でハイエンドチップである Snapdragon 888 を搭載していながら税込みで8万円を切るという安さ
- 今使っている Pixel 3 が Snapdragon800番台だったので、800系以外はあり得ませんでした
- iPhone 並のパフォーマンスが欲しかったら700番台、800番台は必須だと思います(特にゲームで大きな差が出る)
- 端末サイズがコンパクトでありながらパンチホールカメラ+ナローベゼルで 5.9 インチの画面サイズを確保している
- SIM フリーなのでキャリアの余計なアプリとかが入っていない
- SIM フリー端末にしては珍しく FeliCa を搭載している
- Suica に全面的に依存していたのでこれは必須
SoftBank回線でSIMフリースマートフォンを使う時の注意点
前置きが長くなりました。ということで家電量販店で上記端末を購入、そのまま家に持ち帰って家で Pixel に指していた SIM を指してセットアップ、その日は問題なく使え、新端末の快適なパフォーマンスを楽しんでいました。
が、次の日に異変に気付きます。外出時に使ってみるとネットワークに一切つながらないのです。幸い電話は使うことができたのですが、外出中は久しぶりに Wi-Fi 乞食になってしまいました。 *1
もしかしてやっぱり契約変更とかが必要なのかな?と思って家から近い SoftBank ショップで見てもらったのですが、「SIM はそのまま指して使えるはず」「SIM カードや設定には特に問題がない」「端末に問題がありそうだから購入したお店で端末を見てもらって」との回答で解決に至りませんでした…。
仕方がないので翌日端末を購入した家電量販店で見てもらうことにしたのですが、そこで実は SoftBank の SIM カードは大きく分けて次の 3 種類があることを教えてもらいました。 *2
自分が今まで使っていたのは 2 番の SIM カードだったので、3 番への交換が必要だったのでした。家電量販店にはキャリアショップもあったので、そちらに案内してもらい、様々な契約変更を行って、無事にネットワークにつながる SIM が手に入りました(応対した人は別店舗での不手際について申し訳ないとかなり恐縮してました)。
こんな感じでちゃんと使えるようになるまでに色々バタバタしてしまいました。この辺りのガイドラインは Web サイト等できちんと案内して欲しいところです。まあできればキャリアから販売している端末を使ってもらいたいからなんでしょうけど。同じようなことをしようとする人がもしいたら参考になるかと思い、今回の顛末をまとめることにしました。
お陰様で新端末ではこれまで使えなかった5G回線やVoLTEも使えるようになりました。
Zenfone 8について
最後におまけで Zenfone 8 の感想を。
IntelliJ IDEA 2020.2でJavaFXのランタイムが同梱されなくなりました
IntelliJ IDEA の最新版 2020.2 がリリースされましたね。日本語でも新機能について案内する記事がアップされています。
この記事の最後のように次のような個人的に気になる記述がありました。
まず多くの人は「JCEFって何?」ってなると思います。これはアプリケーションに Chromium を組み込めるようにするためのフレームワーク CEF (Chromium Embedded Framework) の Java ラッパーのことです。
- CEF のプロジェクトページ - https://bitbucket.org/chromiumembedded/cef
- JCEF のプロジェクトページ - https://bitbucket.org/chromiumembedded/java-cef
IntelliJ は IDE 内部で使う Web ブラウザコンポーネント (Markdown エディタの HTML プレビューなどで使っています) として今後は JCEF を使うようになったということです。これまでは IDE 内部で使う Web ブラウザコンポーネントとしては JavaFX の WebView を使っていましたが、2020.2 でこれをやめることになります。本件について JetBrains の Blog 記事で説明がありました。
ご存じの通り IntelliJ は Swing をベースに作られています。従って JavaFX の WebView は JFXPanel を通して使うことになりますが、そのために性能やレンダリングの問題を解決できなかったとのことです。
実際、JavaFX と Swing はレンダリングスレッドもタイミングも異なり、Swing アプリの上で JavaFX ノードを描画するときは JavaFX のレンダリングエンジンである Prism エンジンではなく Java2D を使って描画するため、JavaFX のパフォーマンスを 100% 発揮することができないのも確かです。この不整合を解決しようとする計画も過去にはありましたが、 Oracle の JavaFX へのやる気が無くなった ので...。
というわけで上記の記事では IntelliJ のプラグイン開発者に対して今後は JavaFX への依存をやめ、Web ブラウザコンポーネントを使いたいときは JCEF を使うことを促しています。
ですが、JCEF は現在絶賛開発中のステータスで、ユーザーとして利用できるような段階にありません。ビルド方法のガイドはありますが利用方法のガイドはなく、API ドキュメントもありません。ラップ対象の CEF については既に利用可能なステータスにあり (C++ のライブラリです) 、ある程度ドキュメントもあるので、こちらを参照して利用方法を推測することになります。
さすがにこの状態で使うのは辛いので、JetBrains 側でラップした API をプラグイン開発者向けに用意したようです。以下のドキュメントで解説されています。
というわけで IntelliJ IDEA 2020.2 からは JavaFX のランタイムは同梱されなくなります。この点について個人的に1点気になることがありました。
実は IntelliJ は Java IDE の中で唯一 JavaFX Scene Builder を内部に組み込んでいた IDE でした。JavaFX のランタイムが同梱されなくなる 2020.2 ではどうなってしまうのでしょうか?
というわけで早速 FXML ファイルを開いてみました。すると...

「Scene Builder Kit をダウンロードしてくれ」というリンクが表示されました。このリンクをクリックすると次に JavaFX Runtime のダウンロードが求められ、それも行うと次のように Scene Builder が表示されました。

というわけで別途ランタイムをダウンロードする必要があるものの、Scene Builder が使えなくなったわけではないのでご安心ください。
以上、誰も気付かないであろう IDEA 2020.2 の変更点についてのお話でした。